
Spring boot과 Elasticache redis health check
개요
redis의 health check 과정에서 전혀 의도하지 않은 endpoint로 outbound가 발생했다.
redis의 health check를 시도하는듯 하긴 했는데, 입력하지 않은 주소여서 대체 무엇인지 원인 파악을 해보았다.
확인
datadog에서 다음과 같은 현상이 발생하고 있었다.

해당 ip로 전혀 연결을 설정하지 않았었고, 연관되는 dns 조차 없었고 VPC 대역도 아니었다.
의도하지 않은 outbound의 발생이었는데 port가 redis의 default port이므로 무언가 설정이 잘못된것인가 싶었다.
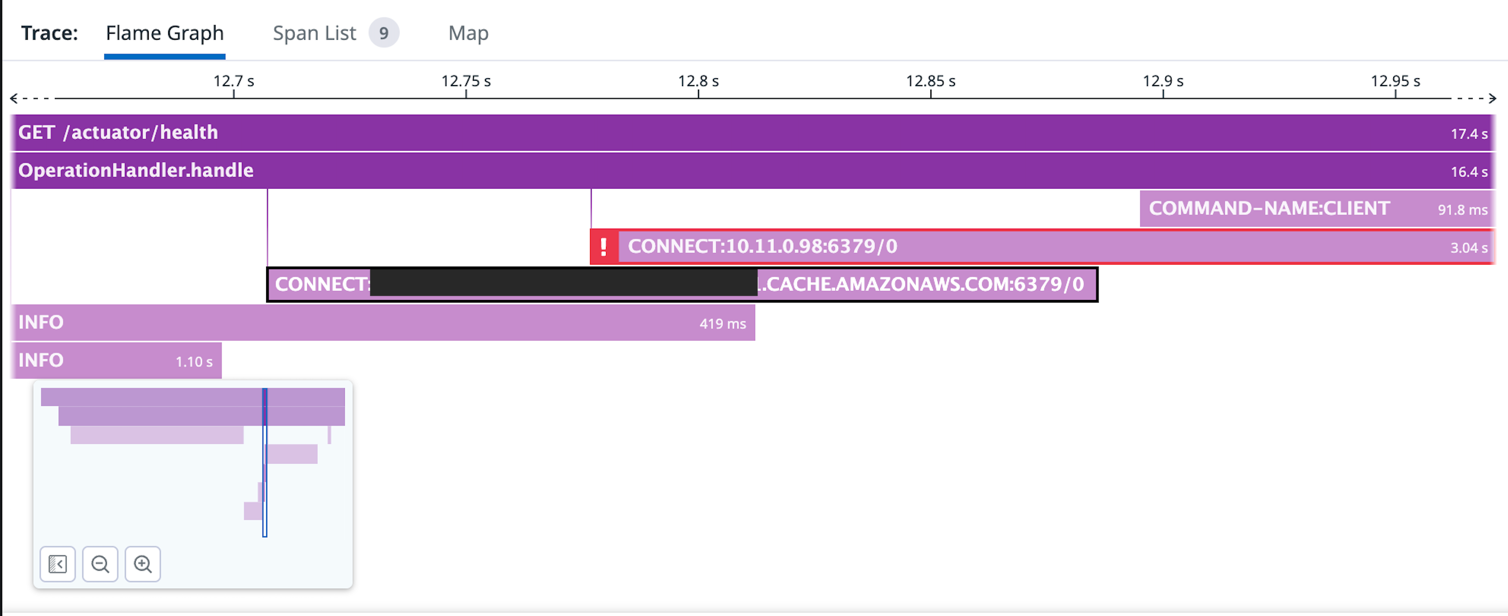
health check은 항상 저 과정대로 하는건 아니고, 보통은 version 체크정도만 하다가 일정 주기마다 좀 더 자세한 헬스체크 과정을 거치는듯 했는데 다음과 같다.
- CONNECT:
<AWS_ELASTICACHE_REDIS_CLUSTER>.cache.amazonaws.com:6379 로 연결 시도(성공) - INFO
- INFO
- CONNECT:
<AWS_ELASTICACHE_REDIS_CLUSTER>.cache.amazonaws.com:6379 로 연결 시도(성공) - CONNECT:10.11.0.98:6379/0(실패)
- COMMAND-NAME:CLIENT(성공)
- INFO
5번이 실패인데, 0번 database를 사용하지도 않았을뿐더러 왜 저기를 보는지 이해가 되지 않았다.
일단 info를 찍어보았다.
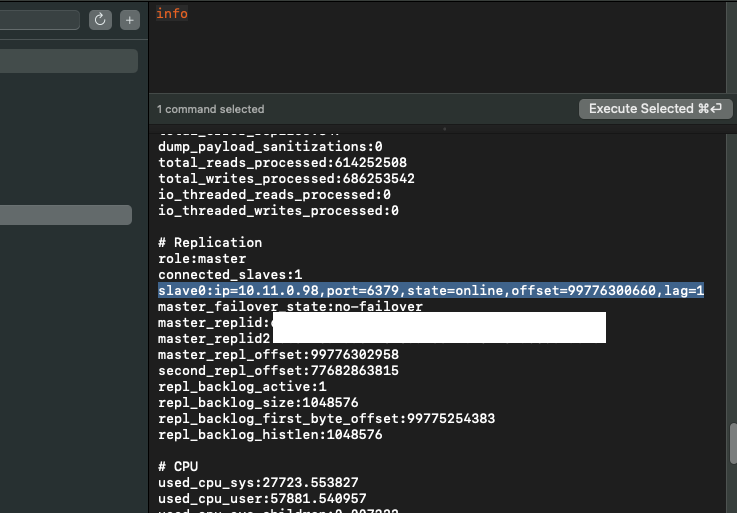
info에 replica 정보로 있었다.
AWS에는 read 전용 endpoint가 있는데, 왜 저기를 사용하지 ? 라고 문의를 해보았는데,
primary와 replica간 data sync를 위해 사용하는 내부 주소로 아마존 관리 영역이라 outbound 열어도 연결은 되지 않을것이라고 했다.
아마도 빠른 싱크를 위해 lookup 과정도 스킵하고 바로 ip로 체크하고 싶었던거같긴 하다.
저기서 timeout이 발생했는데 왜 200 OK 응답으로 health check 자체는 성공했는지 체크 해보았다..
spring actuator 의존성을 넣게 되면 RedisReactiveHealthIndicator 라는 HealthIndicator가 자동으로 생기게 된다.
private Mono<Health> doHealthCheck(Health.Builder builder, ReactiveRedisConnection connection) {
return this.getHealth(builder, connection).onErrorResume((ex) -> {
return Mono.just(builder.down(ex).build());
}).flatMap((health) -> {
return connection.closeLater().thenReturn(health);
});
}
private Mono<Health> getHealth(Health.Builder builder, ReactiveRedisConnection connection) {
if (connection instanceof ReactiveRedisClusterConnection clusterConnection) {
return clusterConnection.clusterGetClusterInfo().map((info) -> {
return this.fromClusterInfo(builder, info);
});
} else {
return connection.serverCommands().info("server").map((info) -> {
return this.up(builder, info);
});
}
}
private Health up(Health.Builder builder, Properties info) {
return RedisHealth.up(builder, info).build();
}info에서 server쪽을 돌면서 up 체크를 하는데, 저기서 redis_version 정보가 있을 경우에 연결에 성공했다고 판단하고 반환하게 된다.
일단 서버 정보여서 연결을 시도했으나, timeout나서 다른 key를 또 체크하고 그러다가 redis_version을 찾았기 때문에 health check 로직 자체에서는 성공으로 판단되는듯..
결론
아마존에서 managed 서비스로 redis를 사용할 경우 자동으로 설정되는 값들이라 변경을 진행하진 않았다.
저게 내부적으로 정한 timeout 3초에 걸리지만 매 health check시마다 진행되는건 아니고, 일정 주기마다 진행되어 서비스에 큰 영향을 미치지는 않을 것이라고 생각되었다.
다만 의도하지 않은 outbound라서 좀 그렇긴 한데, health check을 목적으로 진행되는거고, redis용 health check indicator를 다시 작성하기에는 현재 여건상 아니라고 판단되어 우선 known issue로 두었다.
요즘 보안문제로 공급망 공격(XZ utils 기사) 등이 핫한데, 아무리 star수 등이 높더라도 뭔가 새로운 라이브러리등을 도입한다면 원치않는 동작을 하는지 주기적으로 잘 보긴 해야할듯 싶다.
XZ utils도 보면 결국 오픈소스 관리자를 피곤하게 하고, 계속 신규 기능, 일정등으로 압박하면서 새로운 contributor가 신뢰를 얻어 관리 권한을 부여받게되고 그 순간 돌변해서 백도어가 삽입되는 공격이다.
개발하면서 기능 개발도 좋지만 보안에도 관심을 놓지 말아야할듯 하다.
또한 health check 시에 주의해야 할 점이 있다.
현재 서비스에서 Redis가 반드시 필요하기 때문에 indicator를 재정의하지 않은것이지, 서비스가 만약 redis를 캐시용도로만 쓰고 redis 장애 시 DB 접근하여 서비스 제공이 가능하고, kubernetes 환경이나 AWS에 ALB등이 적용되어 있다면 몇가지를 더 고려해야 한다.
kubernetes는 별다른 설정을 하지 않는다면 livenessProbe에 의해 health check 실패 시 pod가 재시작된다.
이는 redis 하나 장애로 서비스 장애, 나아가서 전체 장애로 이어질 수 있다.
ALB와 연결되어 target group에 엮여있다면 마찬가지로 health check에 걸려 application은 올바른 동작상태일지라도, 트래픽을 받지 못한다.
이는 특정 서버에만 트래픽이 몰리거나, 1대일경우 순단이 발생할 수 있고 동일 코드일 경우 결국 장애로 이어질 수 있기 때문이다.